
지난 3편에 이어,
Garbage Collection(이하 GC, 가비지 컬렉션)의 알고리즘 중
Tracing GC(추적 기반)에 대해 계속 알아본다.
다시 말하지만 Tracing GC에서는
아래 알고리즘들에 대해 작성할 예정이며,
지금까지 세 개의 알고리즘에 대해 알아보았다.
- Mark-Sweep Algorithm
- Mark-Sweep-Compact Algorithm
- Tri-color Marking Algorithm (Incremental GC)
- Copying Algorithm (Incremental GC)
- Generational Algorithm (Incremental GC)
이번 글에서는 앞서 살펴보았던
Mark-Sweep Algorithm의 문제인
Fragmentation(단편화) 이슈를 해결하기 위해 탄생한
Copying Algorithm에 대해 알아보고,
Copying Algorithm을 기반으로 발생되었으며
최근 많은 프로그래밍 언어에서 사용 중인
Generational Algorithm에 대해 알아본다.
Copying Algorithm
개념
Copying Algorithm 역시
단편화 문제를 해결하기 위해 제시된 방법이며,
이전에 살펴보았던 Mark-Sweep Algorithm처럼
Mark(마킹)를 하지 않고 아예 메모리를 옮겨버린다.
Cheney's Algorithm이 대표적인 Copying Algorithm인데,
Heap(힙) 영역을 Active(활동하는 공간)와 InActive(활동하지 않는 공간),
두 개의 같은 크기의 공간으로 나누어
Active 영역에만 객체를 할당하는 방식이다.
만약 Active 영역이 꽉 차게 되면,
Active 영역에서 GC를 수행하여 살아남은 객체를
InActive 영역으로 Copying(복사)하고,
Active와 InActive 영역을 서로 바꾼다.
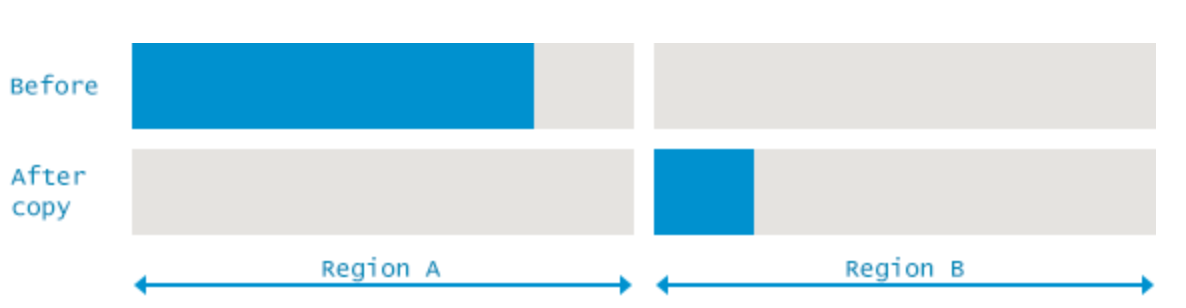
위의 그림으로 예를 들어 보자면,
두 개의 메모리를 A, B라고 했을 때
(1) 처음에는 모든 메모리를 A에 할당을 한다.
(2) 그러다가 A가 가득 차는 등으로 인해 GC가 실행되면
프로그램은 잠시 Suspend(일시중지) 상태가 되고,
A에서 살아남은 메모리를 모두 B로 복사한다.
이 과정이 끝나게 되면 B에는
A에서 접근 가능한 메모리들의 사본만이 있게 되고,
(3) A는 Garbage 객체들만 존재하므로 A 메모리를 비워버린다.
(4) 그다음 과정에서는 B에 메모리를 할당하다가
또다시 GC가 실행되면 A로 복사하고,
(1)부터 (4)까지의 과정을 반복하게 된다.
이처럼,
한 공간의 메모리를 조사하며
접근 가능한 메모리는 바로바로 다른 공간에 옮겨버리면
어디까지 조사했는지 알 수 있으므로
Incremental GC(점진적 GC)를 수행한다고 할 수 있다.
장점
Copying Algorithm의 가장 큰 장점은
메모리를 재배열할 수 있어서 단편화 문제가 해결된다는 것이다.
GC가 완료되면,
새로운 공간에 단편화 없이,
연속된 메모리 공간에 차곡차곡,
재배열이 되기에 캐시 효율이 높아진다.
이러한 장점 덕분에,
아래에서 알아볼 Generational(세대별) Algorithm이
Copying Algorithm을 기반으로 발전시킨 형태이며,
Copying Algorithm은 최근에도 비교적 많이 사용되는 방식이다.
또 다른 장점도 존재하는데,
처음부터 아예 메모리를 할당해두고 시작하기 때문에
Heap(힙) 영역의 메모리 할당을
Stack(스택)처럼 빠르게 할 수 있다는 것이다.
단점
하지만 처음부터 메모리를 잡아두고 시작하다 보니
메모리 공간을 많이 사용하게 되며,
실제로 사용하는 메모리 공간은
전체 Heap 영역의 절반 정도밖에
사용하지 못한다는 공간 활용의 비효율성이 존재한다.
뿐만 아니라 Copying(복사)이라는 작업의 오버헤드가 존재하며,
복사하는 과정에서 메모리의 주소가 바뀌므로
포인터를 이용한 접근을 포기하거나,
메모리의 주소가 바뀔 때마다
모든 메모리의 주소를 갱신해야 한다는 단점이 존재한다.
또한 프로그램의 Suspend(일시중지) 현상도 존재한다.
Generational Algorithm
개념
우리보다 월등히 똑똑한 개발자들이 객체의 라이프 사이클을 자세히 살펴보니,
한 가지 특이한 현상을 발견했다.
객체에 메모리를 할당 후,
해당 객체가 사용하지 않는 Garbage(쓰레기)가 될 때까지
걸리는 시간을 추적했을 때,
대부분의 객체는 잠깐 사용되고 금세 버려지며,
반대로 오래 살아남아 쓰이는 경우는
"그리 많지 않다"는 것이다.
이러한 현상을 토대로
아래 두 가지 가정(Weak Generational Hypothesis)을 전제 삼아
만들어진 방식이 바로 Generational Algorithm이다.
(1) 대부분의 할당된 객체는 오랫동안 참조되지 않는다.
(2) 오래된 객체에서 젊은 객체로의 참조는 거의 없다.
잠깐 사용되고 금세 버려지는 객체를
상대적으로 크기가 작은 "New(Young)" 영역에 할당하고,
New(Young) 영역에서 기준 시간 이상으로
오래 살아남은 객체가 있다면
"Old" 영역으로 이동시켜
말 그래도 "세대"를 구분하는 방법이다.
이 세대를 나누는 기준은 구현 방식마다 상당히 다른데,
Stack(스택) 영역을 New(Young) 영역으로 쓸 수도 있고,
Heap(힙) 영역에 임의로 할당해서 쓸 수도 있지만,
대부분의 경우 힙 영역을 사용하므로
이 글에서는 힙 영역을 기준으로 설명한다.
이 New(Young) 영역의 크기는 보통 해당 플랫폼이나
언어가 최소로 필요로 하는 메모리보다 조금 많게 잡는 편이며,
몇몇 구현의 경우에는 New(Young)와 Old 영역 2개가 아니라
임의의 개수만큼 나누는 경우도 있는데,
예를 들어, 맨 처음 할당된 Old를 0세대,
그다음을 1세대,... , 다음을 n세대처럼 사용한다.

위의 그림을 보면,
객체는 Young(New) Generation에 할당되고
GC가 수행될 때마다 살아남은 객체에 Age를 기록한다.
Java 진영의 대표적인 JVM 구현인
아래 HotSpot JVM에서는
이 Age의 임계값의 기본값을 31로 세팅한다.
(객체 Header에 Age를 기록하는 부분이 6 Bits이고,
6 Bits로 표현할 수 있는 수치가 32이기 때문)
이 Age 역할은 해당 객체가 몇 번 살아남았는지 기록하는 것이며,
특정 임계값을 넘어서게 되면
Old Generation으로 Copy 하는 작업(Promotion)을 진행한다.
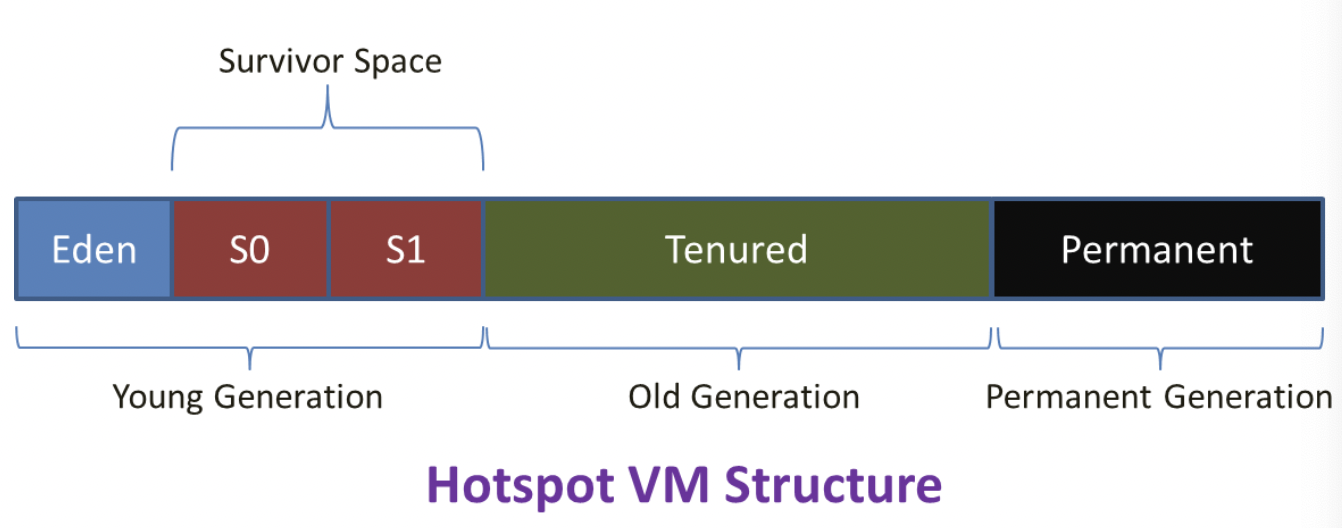
HotSpot JVM에서는 구조가 좀 다른 것을 볼 수 있는데,
이와 관련해서는 따로 포스팅을 할 예정이다.
(글이 너무 길어져서;;)
장점
위에서 언급한 것처럼,
대부분의 객체는 Young(New) Generation에서 살다가 쓰레기가 되기 때문에
Young(New)에서 Old로의 Copying 작업을 최소화시킬 수 있고,
상대적으로 작은 영역만 추적하면
적은 시간과 비용으로 짧은 시간 안에
쓰레기 메모리를 확보할 수 있게 된다.
또한, Copying 작업이 이루어지며
Compaction 작업도 수행되기 때문에 단편화 문제도 해결될 수 있다.
그리고 Old 영역에서 쓰레기 메모리를 수집하는 Major-GC와
New 영역에서만 수집하는 Minor-GC로 나눠
GC를 수행할 수 있고,
위에서 알아본 Cheney's Algorithm을 접목하여
단편화를 줄일 수도 있는 등 여러 모로 이점이 많기에
Tracing GC(추적 기반 GC)를 사용하는
현재의 많은 언어들(Java, C#, Go 등)은 이 기법을 사용하고 있다.
긴 여정이었다..
하지만 Generational GC의 경우,
최근의 언어들이 많이 사용하는 GC이기 때문에
따로 포스팅을 작성하여 더 자세히 살펴볼 예정이다.
이번 글의 시리즈는 아래 글들을 참고하여 작성했다.
끝!