
Index(이하 인덱스)는 DB를 다루다 보면 필연적으로 듣는 단어이다.
본격적으로 글에 들어가기 전에 인덱스에 대해 간단하게 설명하자면,
DB 데이터 조회 성능 향상을 위해 사용한다.
대용량 데이터를 담고 있는 DB 테이블에서 우리에게 필요한 데이터를 빨리 찾으려면
이 '인덱스'라는 녀석의 도움이 필요하다.
인덱스가 아예 없거나 적절한 인덱스를 찾지 못하면,
어마무시한 데이터가 담겨있는 테이블 전체를 읽어야 하기 때문에 데이터 조회 시간이 오래 걸릴 것이다.
이 인덱스에 대해 앞으로의 글들을 통해 보다 자세히 알아보자.
본 글들은 아래 글들의 내용을 토대로 작성했다.
DB 성능과 관련된 사항들
인덱스에 대해 알아보기 전,
데이터베이스의 성능과 관련된 사항에는 크게 네 가지 정도가 존재하는데,
애플리케이션의 응답 시간 단축과 성능 향상 방법 중 하나인 DB 데이터 조회 속도를 빠르게 하려면,
아래 네 가지의 데이터베이스 Activity가 적게 발생하도록 쿼리를 작성해야 한다.
(1) 프로세서
컴파일(실행계획 생성),
연산(SORT, JOIN, DATA, CONVERSION),
LOCK 관리 등이 존재한다.
(2) LOCK
Row, Table, Library cache LOCK 등이 존재한다.
(3) Network I/O
Application Server와 DB Server들 간의 요청,
혹은 결과 데이터 전송을 뜻한다.
이러한 데이터 전송 간의 네트워크 시간이 꽤 오래 걸리기 때문에 해당 시간을 최소한으로 해야 하는데,
해결책은 원하는 데이터를 한방에 가져오는,
이른바 "한방 쿼리"를 짜는 것이다.
(4) 데이터 I/O
말 그대로 데이터를 입력되고(Input) 나가는 것(Out)인데,
DB 인덱스 개념이 여기에 속한다.
개념
인덱스란, DB 내 저장된 데이터의 "주소"를 갖고 있는 것이다.
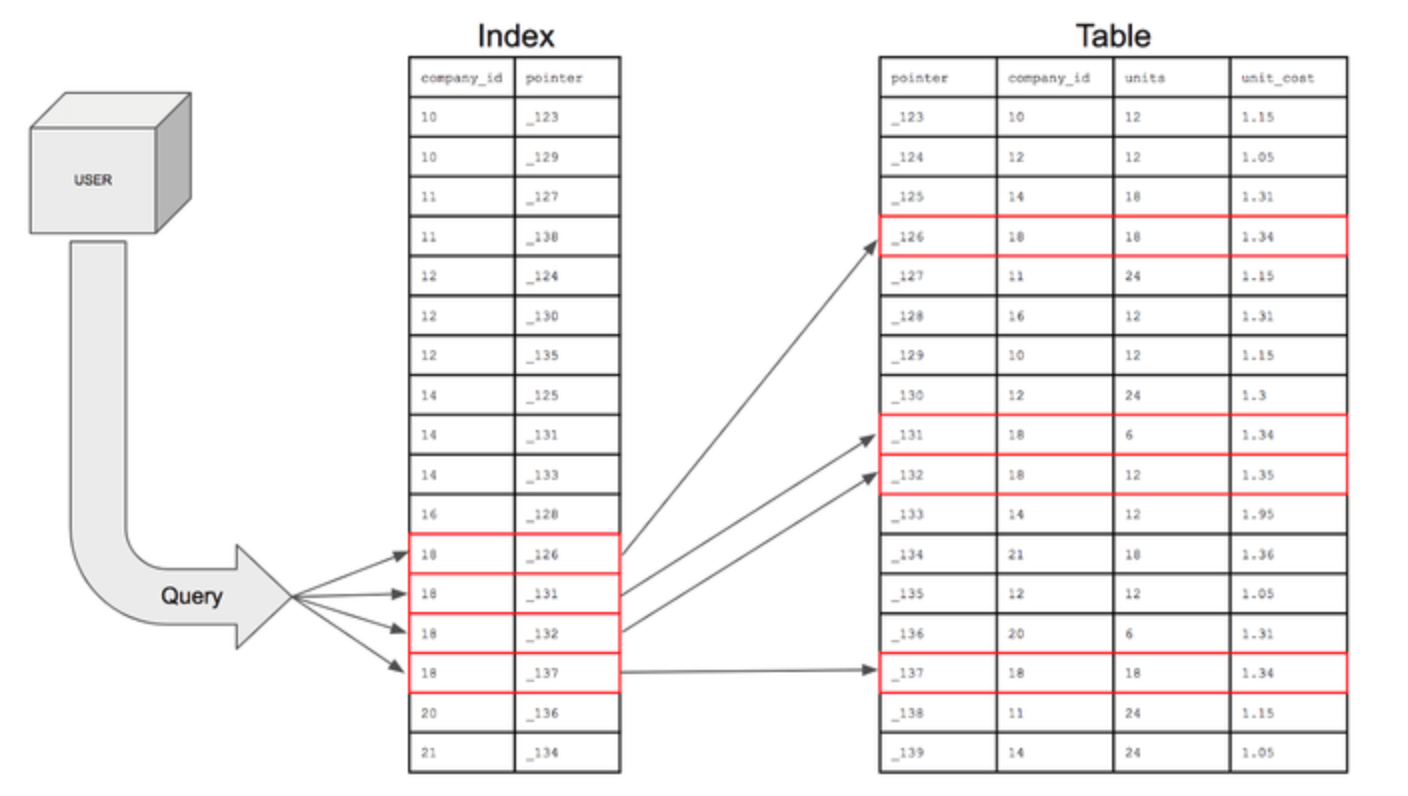
인덱스는 위 그림처럼 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 Key로 삼고,
Key에 해당하는 OID(레코드의 물리적 주소 값)가 저장되어 있다.
테이블의 다른 세부 항목들은 갖고 있지 않기 때문에,
보통의 테이블을 저장하는 데 필요한 디스크 공간보다 작은 디스크 공간을 필요로 한다.
즉, 책으로 비교하자면 일종의 "색인" 페이지로,
SQL 명령문의 처리 속도를 향상하기 위해 생성하는 객체이다.
흔히들 책의 "목차"나 뒤에 있는 "찾아보기"를 예시로 많이 드는데,
나무위키의 목차에 대한 설명을 읽어보면 아래처럼 작성되어 있는 문장을 볼 수 있다.
"비슷한 개념인 색인(인덱스)과 가끔 혼동하는 사람이 있는데, 이 둘은 분명히 다른 개념이다.
목차는 책 앞에서 '이 책 내용은 뭐다' 하고 순서대로 보여주는 것이고,
색인은 책 뒤에서 '그 내용을 알고 싶으면 몇 페이지로 가라'라고 지름길을 안내해주는 것으로,
흔히 '찾아보기'라고 되어 있는 부분이 바로 색인이다."
그래서 "목차"보다는 "색인"이 더 맞는 비유다.
장점
인덱스를 사용하는 이유이자 장점은 크게 보자면 딱 하나뿐이다.
방금 인덱스의 개념을 "DB 데이터의 주소를 갖고 있는 것"이라고 했다.
그렇다면 장점은 당연하게도, 원하는 데이터를 빠르게 찾을 수 있다는 것이다.
그럼으로 인해 전반적인 시스템의 부하를 줄일 수 있기도 하지만, 데이터 조회가 빠르다는 것이 핵심이다.
'어? 이것밖에 장점이 없는데 왜 쓰지?' 생각이 든다.
그 이유는, 글 하단부의 '그럼에도 불구하고' 파트를 참고하자.
단점
하나였던 장점에 비해, 단점은 크게 세 가지다.
(1) 타 성능 악영향
인덱스는 데이터 조회(SELECT)를 제외한 모든 동작,
즉, INSERT / UPDATE / DELETE 성능에 영향을 미친다.
위 세 가지 동작은 데이터를 삽입하고 수정하고 삭제하는데,
그러한 행위들로 인해 인덱스를 걸어둔 컬럼의 데이터가 바뀌면 인덱스 테이블의 수정도 필요하기 때문에,
데이터의 삽입 / 수정 / 삭제 작업의 두 번 이루어지게 되는 것이다.
(2) 추가 저장 공간 필요
DB에 저장된 데이터의 주소를 인덱스의 Key 값으로 가지려면 별도의 공간에 저장하므로 추가 저장 공간이 필요하다.
때문에 인덱스를 사용하는 시스템을 설계할 때,
인덱스 영역을 전체 테이블 영역의 30 ~ 50%까지 잡아 놓을 만큼 저장 공간이 꽤나 많이 필요하다.
(3) 공수 필요
공수란, "장인 공"에 "셀 수"를 사용하는 단어로,
일정한 작업에 필요한 인원수를 노동 시간이나 노동 일로 나타내는 수치이다.
인덱스를 생성하고 주기적으로 관리할 공수, 즉, 인력과 시간이 들어간다.
그럼에도 불구하고
RDBMS(관계형 데이터베이스 관리 시스템)에서 인덱스는 필수다.
일반적인 OLTP(OnLine Transaction Processing, 온라인 트랜잭션 처리, 설명글 링크) 시스템에서
데이터 조회 업무가 90% 이상이기 때문이다.
그러한 조회 업무의 검색 속도 향상은 시스템 부하를 감소시켜, 같은 시간 내에 더 많은 업무 처리가 가능해진다.
그렇기 때문에 위의 단점에서 알 수 있듯,
(1) 규모가 작지 않은 테이블에서
(2) INSERT / UPDATE / DELETE가 자주 발생하지 않는 컬럼,
(3) 혹은 JOIN / WHERE / ORDER BY에 자주 사용되는 컬럼,
(4) 혹은 데이터의 중복도가 낮은 컬럼 등에
인덱스를 사용하면 좋다.
웹 애플리케이션의 백엔드 성능을 높이려고 종종 실행하는 SQL 튜닝이란,
SQL이 위에서 알아본 인덱스를 활용하도록 SQL을 수정하는 것이라고 할 수 있다.
그러니 인덱스를 잘 이해하고 있다면 더 좋은 SQL을 작성할 수 있을 것이고,
훨씬 더 성능 좋은 애플리케이션을 만들 수 있다.
다음으로는 인덱스의 구조에 대해 깊게 알아본다.
끝!
'Study > Database' 카테고리의 다른 글
| [DB] 인덱스란? - (2) 구조, B-Tree 계열을 쓰는 이유 (0) | 2021.06.07 |
|---|---|
| [DB] DCL, DDL, DML이란? (0) | 2021.06.02 |
| [DB][MSSQL] PIVOT, UNPIVOT으로 여러 컬럼 합치기 (0) | 2021.04.08 |
| [DB] SQL 작성 표준 가이드 (0) | 2021.02.25 |
| [DB] 트랜잭션(Transaction)이란? (+ ACID) (0) | 2021.02.12 |